Multi-Armed Bandit (MAB) is a sequential decision-making framework used to optimize the allocation of resources among multiple competing options (or “arms”) to maximize cumulative rewards over time. It is particularly useful in scenarios where the true performance of each option is unknown and must be learned through experimentation. It is an adaptive experimentation approach inspired by the problem of a gambler facing multiple slot machines (one-armed bandits) and trying to maximize their total winnings by choosing which machines to play and how often.
In an A/B Testing context, it dynamically allocated traffic to different variations based on real-time performance, balancing exploration (testing less-known options) and exploitation (favoring the best-known option).
Advantages of Multi-Armed Bandit
- Dynamic Allocation: Adjusts traffic allocation in real-time, sending more users to better-performing variations, reducing wasted impressions on underperforming options.
- Faster Convergence: Reaches conclusions more quickly than traditional A/B testing because it learns and adapts during the test.
- Efficient Resource Usage: Maximizes rewards (e.g., clicks or conversions) during the experiment rather than waiting for the test to conclude.
- Handles Multiple Variants: Can test more than two versions simultaneously, making it more efficient for multi-variant experiments.
- Minimizes Opportunity Cost: Reduces the negative impact of exposing users to underperforming variants by quickly shifting traffic to better options.
- Continuous Learning: Operates continuously, making it suitable for long-term optimization and environments with changing user preferences.
Definition
It is a simplified version of Markov Decision Process (MDP), but without state transitions. The goal is to maximize the total reward over a series of trials by choosing from multiple options (arms), each with an unknown reward distribution.
The optimal reward probability of the optimal arm is defined as:
Bandit Strategies
- Epsilon-Greedy
- Upper Confidence Bound (UCB)
- Hoeffding’s Inequality
- Bayesian UCB
- Thompson Sampling
Epsilon-Greedy Strategy
The Epsilon-Greedy strategy is a simple and effective approach to balance exploration and exploitation in the Multi-Armed Bandit problem. It involves choosing the best-known option most of the time while occasionally exploring other options to gather more information.
- Choose each arm once.
- Choose arm in round :
where
- is a constant that controls the exploration rate
- is the number of arms
- is the current time step
- is the minimum difference in mean rewards among arms.
Code Example
Epsilon-Greedy Implementation
import numpy as npimport matplotlib.pyplot as plt
np.random.seed(42)
# Epsilon-Greedy Bandit Algorithmclass EpsilonGreedyBandit: def __init__(self, n_arms, c, delta_min): self.n_arms = n_arms self.c = c self.delta_min = delta_min self.arm_rewards = np.zeros(n_arms) # cumulative rewards for each arm self.arm_counts = np.zeros(n_arms) # number of times each arm was pulled self.total_counts = 0 # total number of pulls
def calculate_epsilon(self): total_counts = self.total_counts + 1 # to avoid division by zero epsilon = min(1, (self.c * self.n_arms) / (self.delta_min ** 2 * total_counts)) return epsilon
def select_arm(self): epsilon = self.calculate_epsilon() if np.random.rand() < epsilon: return np.random.randint(self.n_arms) # Explore else: return np.argmax(self.arm_rewards / (self.arm_counts + 1e-5)) # Exploit
def update(self, arm, reward): self.arm_rewards[arm] += reward self.arm_counts[arm] += 1 self.total_counts += 1
# Simulation three ads with different reward distributionstrue_mean_rewards = [0.3, 0.5, 0.7]reward_distributions = [lambda: np.random.binomial(1, p) for p in true_mean_rewards]
# Parametersn_arms = len(true_mean_rewards)c = 1delta_min = min(true_mean_rewards)
# Initialize banditbandit = EpsilonGreedyBandit(n_arms, c, delta_min)
# Run simulationn_rounds = 10000rewards = []ad_selections = []cumulative_rewards = np.zeros(n_rounds)traffic_allocation = np.zeros((n_rounds, n_arms))
for t in range(n_rounds): selected_ad = bandit.select_arm() ad_selections.append(selected_ad) reward = reward_distributions[selected_ad]() rewards.append(reward) bandit.update(selected_ad, reward) cumulative_rewards[t] = cumulative_rewards[t-1] + reward if t > 0 else reward traffic_allocation[t] = bandit.arm_counts
# Plot resultsplt.figure(figsize=(12, 6))for arm in range(bandit.n_arms): plt.plot(traffic_allocation[:, arm], label=f'Ad {arm+1} (True Mean: {true_mean_rewards[arm]})')plt.title('Traffic Allocation Over Time')plt.xlabel('Rounds')plt.ylabel('Number of Selections')plt.legend()plt.grid()
# estimatedestimated_rewards = bandit.arm_rewards / (bandit.arm_counts + 1e-5)plt.figure(figsize=(12,6))plt.plot(range(n_rounds), cumulative_rewards, label='Cumulative Rewards', color='blue')plt.xlabel('Rounds')plt.ylabel('Total Reward')plt.legend()plt.grid()
# traffic allocationplt.figure(figsize=(12,6))plt.bar(range(bandit.n_arms), traffic_allocation[-1], label='Traffic Allocation', color=['blue', 'orange', 'green'])plt.xticks(range(bandit.n_arms), [f'Ad {i+1}' for i in range(bandit.n_arms)])plt.title('Final Traffic Allocation to Each Ad')plt.xlabel('Ads')plt.ylabel('Total Traffic Allocation')plt.legend()plt.grid(True, axis='y')Output
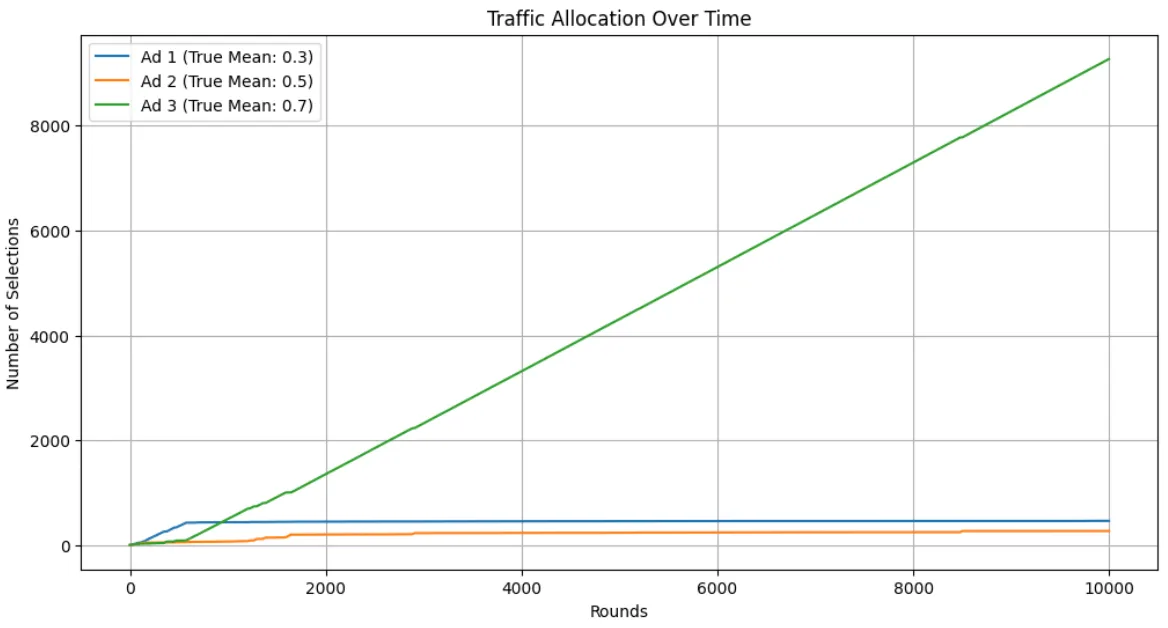
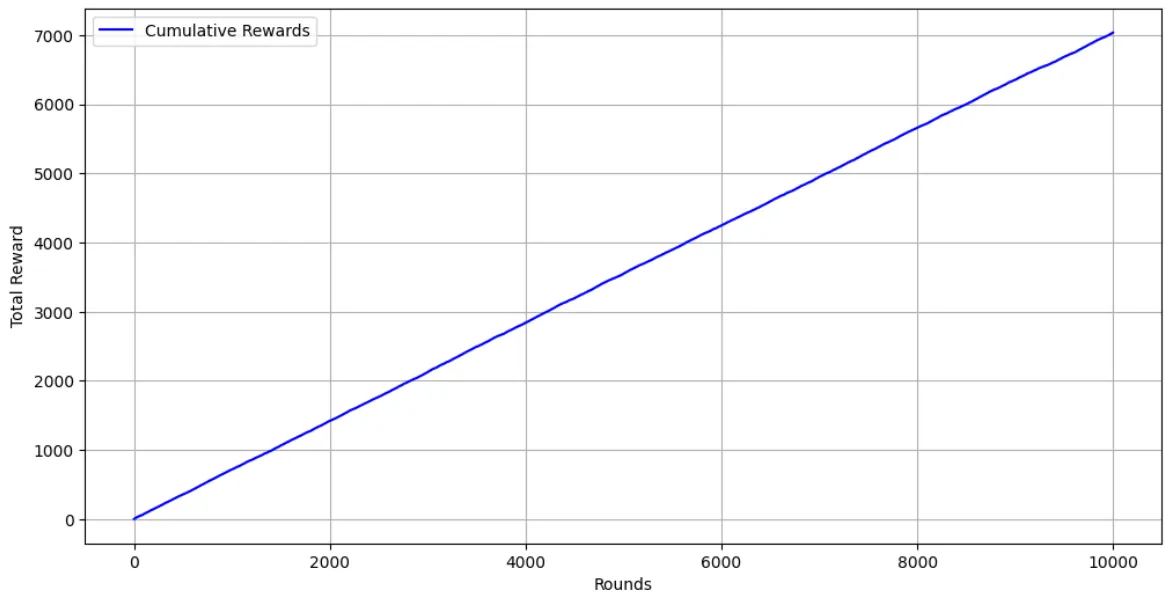
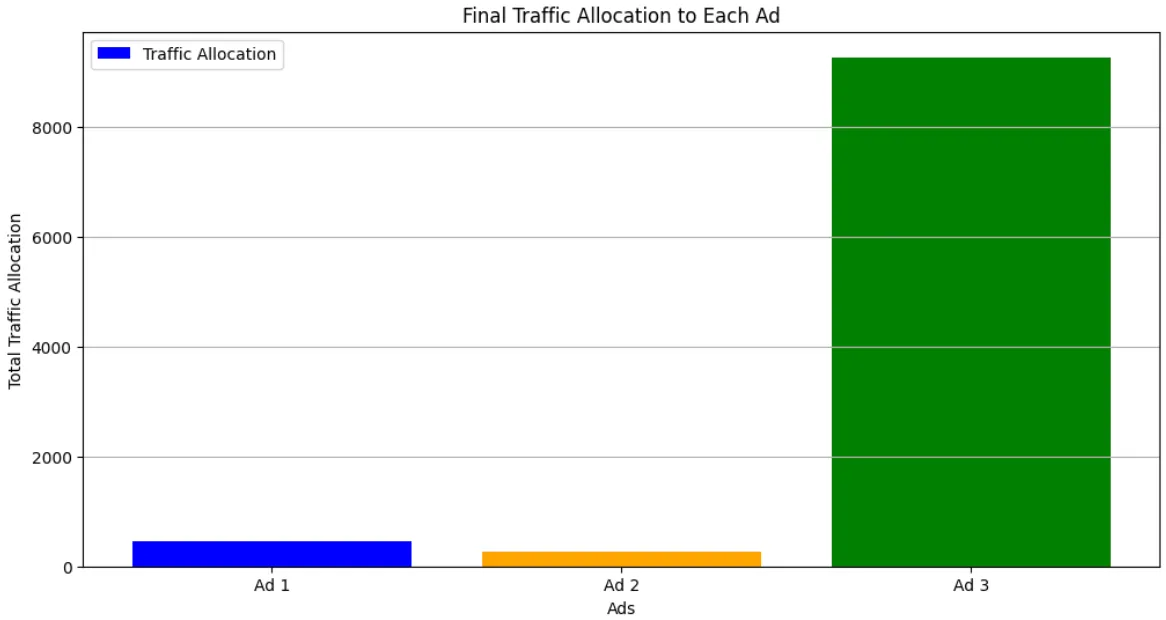
Thompson Sampling Implementation
Thompson Sampling is a Bayesian approach to the Multi-Armed Bandit problem that balances exploration and exploitation by sampling from the posterior distribution of each arm’s reward. It selects arms based on the probability that they are the best option, given the observed data.
- Initialize prior distributions for each arm (e.g., Beta distribution for Bernoulli rewards).
- For each round:
- Sample a reward probability from the posterior distribution of each arm.
- Select the arm with the highest sampled probability.
- Update the posterior distribution based on the observed reward.
import numpy as npimport matplotlib.pyplot as plt
np.random.seed(42)
# Epsilon-Greedy Bandit Algorithmclass SamplingBandit: def __init__(self, n_arms): self.n_arms = n_arms self.alpha = np.ones(n_arms) self.beta = np.ones(n_arms) self.arm_rewards = np.zeros(n_arms) # cumulative rewards for each arm self.arm_counts = np.zeros(n_arms) # number of times each arm was pulled self.total_counts = 0 # total number of pulls
def select_arm(self): sample_means = np.random.beta(self.alpha, self.beta) return np.argmax(sample_means)
def update(self, arm, reward): self.arm_rewards[arm] += reward self.arm_counts[arm] += 1 self.total_counts += 1 if reward == 1: # reward observed self.alpha[arm] += 1 else: # no reward self.beta[arm] += 1
# Simulation three ads with different reward distributionstrue_mean_rewards = [0.3, 0.5, 0.7]reward_distributions = [lambda: np.random.binomial(1, p) for p in true_mean_rewards]
# Parametersn_arms = len(true_mean_rewards)c = 1delta_min = min(true_mean_rewards)
# Initialize banditbandit = SamplingBandit(n_arms)
# Run simulationn_rounds = 10000rewards = []ad_selections = []cumulative_rewards = np.zeros(n_rounds)traffic_allocation = np.zeros((n_rounds, n_arms))
for t in range(n_rounds): selected_ad = bandit.select_arm() ad_selections.append(selected_ad) reward = reward_distributions[selected_ad]() rewards.append(reward) bandit.update(selected_ad, reward) cumulative_rewards[t] = cumulative_rewards[t-1] + reward if t > 0 else reward traffic_allocation[t] = bandit.arm_counts
# Plot resultsplt.figure(figsize=(12, 6))for arm in range(bandit.n_arms): plt.plot(traffic_allocation[:, arm], label=f'Ad {arm+1} (True Mean: {true_mean_rewards[arm]})')plt.title('Traffic Allocation Over Time')plt.xlabel('Rounds')plt.ylabel('Number of Selections')plt.legend()plt.grid()
# estimatedestimated_rewards = bandit.arm_rewards / (bandit.arm_counts + 1e-5)plt.figure(figsize=(12,6))plt.plot(range(n_rounds), cumulative_rewards, label='Cumulative Rewards', color='blue')plt.xlabel('Rounds')plt.ylabel('Total Reward')plt.legend()plt.grid()
# traffic allocationplt.figure(figsize=(12,6))plt.bar(range(bandit.n_arms), traffic_allocation[-1], label='Traffic Allocation', color=['blue', 'orange', 'green'])plt.xticks(range(bandit.n_arms), [f'Ad {i+1}' for i in range(bandit.n_arms)])plt.title('Final Traffic Allocation to Each Ad')plt.xlabel('Ads')plt.ylabel('Total Traffic Allocation')plt.legend()plt.grid(True, axis='y')